
Hierarchical Attention Network
Intro
현재 tranformer류가 대세가 되면서 nlp task들을 주로 BERT로 해오곤 있었다. Named Entity Recognition 이나 classification의 문제 등 필요한 pre-trained 모델을 활용히고 task에 따라 last-layer만 교체하는 식으로 풀어나가도 그 성능은 엄청나기 때문이다. 그러나 최근, Document Classification의 문제를 해결할 일이 생겼는데,
물론 우리의 BERT는 엄청난 performance를 해결하지만, 결국 BERT max_len의 한계에 sentence마다 classification 후 sentences 대한 predicition의 set 중 가장 빈도가 많은 것을 document로 분류하였다.
이는 사실 정상적인 접근이라 보기 힘든게 document 자체에 대한 loss를 구하기 힘들다.
더 좋은 방법을 찾던 중 같이 논문스터디를 진행하고 있는 @류태선 님 덕분에 해당 model을 알게 되었다. bert에 비해 성능이 항상 좋을거라 보장은 못 하지만, 더 가벼운 모델로서 활용이 가능하고, 현재 생각드는 건 bert encoder의 output들을 활용하면 좋지 않을까 생각한다.
MS에서 비슷한 연구를 진행한 것 같다.
Model
모델은 실은 정말 간단하다. tranformer가 나오기 전에 등장한 모델로 구조는 다음과 같다.
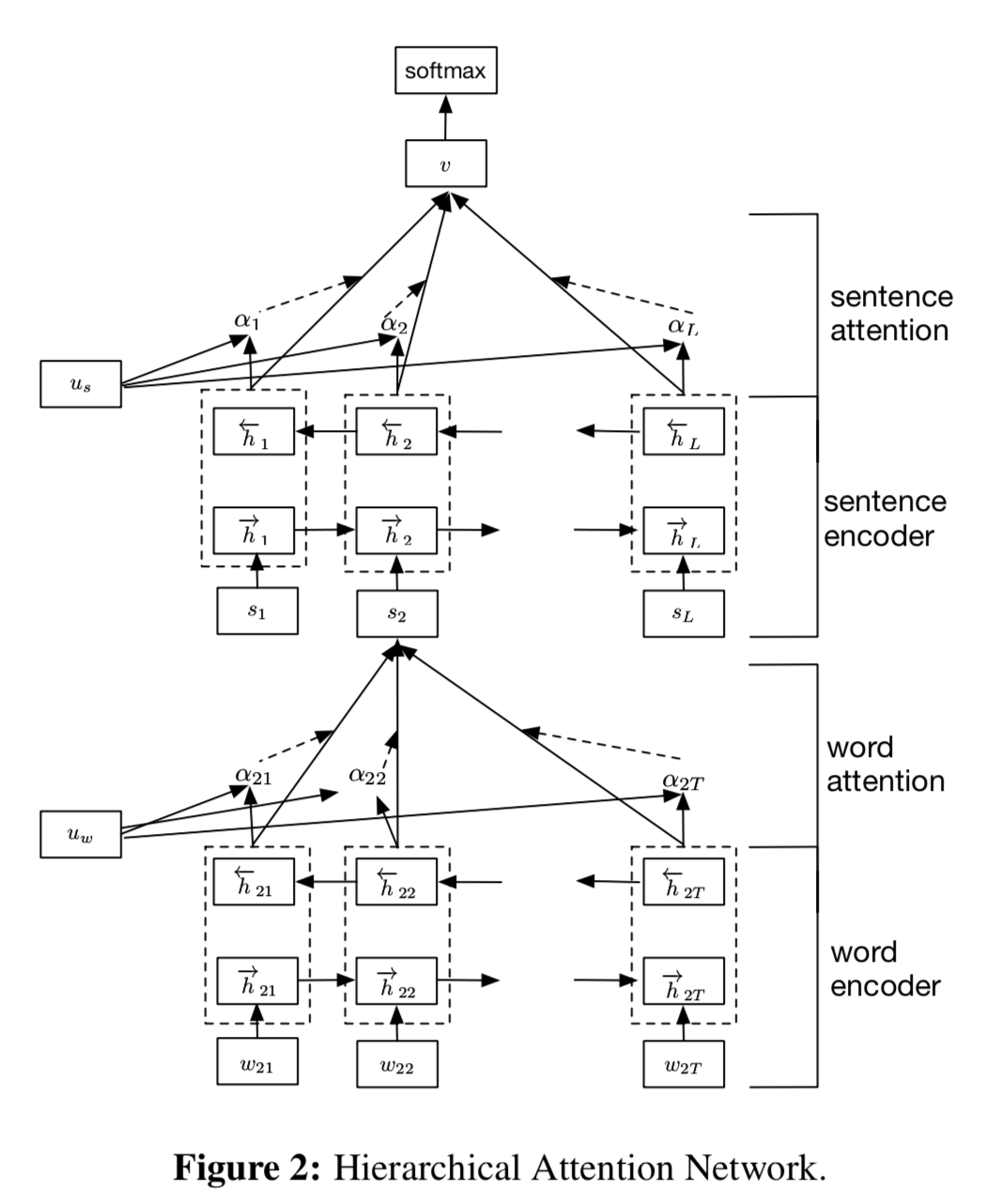
Word Encoder - Word Attention - Sentence Encoder - Sentence Attention
직관적으로 Attention을 통해 informative word를 활용하고, 이를 기반으로 informative sentence를 찾는다는 것이다.
결국 마지막 v는 한 document 안의 sentence들에 대한 모든 정보가 summarize 되었다고 이해하면 된다.
모델의 구현부 1
"""
@author: Viet Nguyen <nhviet1009@gmail.com>
"""
import torch
import torch.nn as nn
from src.sent_att_model import SentAttNet
from src.word_att_model import WordAttNet
class HierAttNet(nn.Module):
def __init__(self, word_hidden_size, sent_hidden_size, batch_size, num_classes, pretrained_word2vec_path,
max_sent_length, max_word_length):
super(HierAttNet, self).__init__()
self.batch_size = batch_size
self.word_hidden_size = word_hidden_size
self.sent_hidden_size = sent_hidden_size
self.max_sent_length = max_sent_length
self.max_word_length = max_word_length
self.word_att_net = WordAttNet(pretrained_word2vec_path, word_hidden_size)
self.sent_att_net = SentAttNet(sent_hidden_size, word_hidden_size, num_classes)
self._init_hidden_state()
def _init_hidden_state(self, last_batch_size=None):
if last_batch_size:
batch_size = last_batch_size
else:
batch_size = self.batch_size
self.word_hidden_state = torch.zeros(2, batch_size, self.word_hidden_size)
self.sent_hidden_state = torch.zeros(2, batch_size, self.sent_hidden_size)
if torch.cuda.is_available():
self.word_hidden_state = self.word_hidden_state.cuda()
self.sent_hidden_state = self.sent_hidden_state.cuda()
def forward(self, input):
output_list = []
input = input.permute(1, 0, 2)
for i in input:
output, self.word_hidden_state = self.word_att_net(i.permute(1, 0), self.word_hidden_state) # word attention의 결과를
output_list.append(output) # 저장하고
output = torch.cat(output_list, 0)
output, self.sent_hidden_state = self.sent_att_net(output, self.sent_hidden_state) # word attention의 결과를 활용하여 sentence-level attention을 구한다.
return output
References :
-
https://github.com/uvipen/Hierarchical-attention-networks-pytorch/blob/master/src/hierarchical_att_model.py ↩